
개요
이 글에서는 매장 주문 시스템의 실시간 처리 문제를 해결하기 위해 Server-Sent Events(SSE)와 이벤트 로그 테이블을 활용하여 성능을 최적화하는 방법을 설명합니다.
기존 방식의 한계, SSE 선택 이유, 이벤트 기반 최적화 방법, 그리고 실제 성능 개선 수치를 구체적으로 다룹니다.
이 문서를 통해 얻을 수 있는 것:
- 실시간 데이터 처리 시스템 설계 방법
- SSE를 활용한 네트워크 트래픽 최소화 전략
- 대규모 주문 데이터 처리 성능 최적화 경험 공유
실시간 주문 시스템에서 성능 병목을 해결하고, 수십만 건의 데이터에서도 서버 부하 없이 빠르게 반응하는 구조를 만들고 싶다면 이 글이 도움이 될 것입니다.
실시간 주문, 왜 이렇게 어려운가?
매장 주문 시스템을 개발하면서 주문이 들어왔는데 화면에는 바로 표시되지 않는 문제를 확인했다. 문제는 단순히 페이지를 새로고침하면 해결되기도 했지만, 이 방식은 실시간 시스템이라고 부르기엔 너무 부족했다.
목표:
- 주문이 들어오면 페이지를 새로고침하지 않고도 바로 반영되게 만들자.
- 서버와 클라이언트 모두 부하를 최소화하자.
이를 해결하기 위해 다양한 실시간 통신 기술을 검토했다.
실시간 통신 기술 비교
| 방식 | 장점 | 단점 | 사용 예시 |
|---|---|---|---|
| Polling | 구현이 간단함, 모든 브라우저 지원 | 불필요한 요청 발생, 실시간성 저하 | 간단한 알림, 새로고침 기능 |
| WebSocket | 양방향 통신 지원 | 별도 서버 구축 필요, 설정 복잡 | 채팅, 게임, 다중 사용자 협업 |
| SSE (Server-Sent Events) | HTTP 기반, 단방향 실시간 푸시, 간단한 구현 | 단방향 통신만 가능 | 실시간 주문 관리, 금융 데이터 스트리밍 |
SSE를 선택한 이유
Polling은 트래픽이 과도하게 발생하고 실시간 반응성이 부족했다.
WebSocket은 양방향 통신이 필요할 때 강력하지만, 이번 프로젝트는 서버에서 클라이언트로 "주문 상태 알림"만 보내면 충분했다.
따라서, SSE(Server-Sent Events)를 도입하기로 결정했다.
SSE 적용 후 발생한 문제
초기에는 SSE를 통해 주문 상태를 실시간으로 스트리밍하면 모든 문제가 해결될 것으로 예상했다. 하지만 곧 몇 가지 심각한 문제가 드러났다.
주요 문제점
-
초기 접속 시 데이터 부재
- SSE는 이벤트가 발생해야 데이터가 전송된다.
- 새로운 주문이 발생하기 전까지는 아무런 데이터가 표시되지 않아, 사용자 입장에서는 빈 화면만 보였다.
-
불필요한 전체 데이터 전송
- 주문 하나가 변경되어도 전체 주문 목록을 다시 전송했다.
- 주문량이 많아질수록 네트워크 트래픽과 서버 부하가 급격히 증가했다.
-
성능 저하
- 수백, 수천 건까지는 견딜 수 있었지만, 수십만 건 이상으로 증가하면 서버가 과부하로 다운되었다.
해결 방법: 이벤트 로그로 최적화하기
문제 해결을 위해 SSE의 역할을 "데이터 전송"이 아닌 "변경 알림"으로 제한하는 방향으로 접근했다.
개선 전략
- SSE는 주문 변경 신호만 전송
- 변경이 발생하면 클라이언트가 필요한 데이터만 API로 별도 요청
이벤트 로그 테이블 도입
또한, 주문 데이터 자체를 감지하는 대신, 별도의 이벤트 로그 테이블(order_events)을 도입해 주문 변경 사항을 기록하고 감지하도록 설계했다.
CREATE TABLE public.order_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
order_id UUID REFERENCES public.orders(id) ON DELETE CASCADE,
event_type TEXT NOT NULL,
created_at TIMESTAMPTZ DEFAULT now()
);
| event_type | 설명 |
|---|---|
| order_paid | 결제 완료 |
| order_updated | 주문 상태 변경 |
→ orders 테이블 대신 order_events 테이블만 감지하면, 변경이 발생했을 때만 최소한의 데이터로 실시간 업데이트 가능해졌다.
코드: 개선 전후 비교
기존 방식 (비효율적)
supabase
.channel('orders')
.on(
'postgres_changes',
{ event: '*', schema: 'public', table: 'orders' },
async (payload) => {
const { data: orders } = await supabase.from('orders').select('*');
writer.write(
new TextEncoder().encode(`data: ${JSON.stringify(orders)}\n\n`),
);
},
)
.subscribe();
- 주문 하나가 변경돼도 모든 주문 데이터를 다시 내려보냈다.
개선된 방식 (최적화 적용)
supabase
.channel('order_events')
.on(
'postgres_changes',
{ event: 'INSERT', schema: 'public', table: 'order_events' },
(payload) => {
writer.write(
new TextEncoder().encode(
`data: ${payload.new.event_type}:${payload.new.order_id}\n\n`,
),
);
},
)
.subscribe();
- "변경 알림"만 전송하고, 클라이언트가 해당 주문 데이터만 API를 통해 가져오게 변경했다.
성능 비교: 수치로 보는 개선 효과
| 주문 개수 | 기존 방식 (전체 refetch) | 개선된 방식 (이벤트 기반) |
|---|---|---|
| 100개 | 5ms | 3ms |
| 10,000개 | 150ms | 5ms |
| 1,000,000개 | 3.2s (서버 과부하 발생) | 6ms |
주문 수가 많아질수록 개선 효과가 극적으로 커졌다.
실시간 주문 업데이트 시연
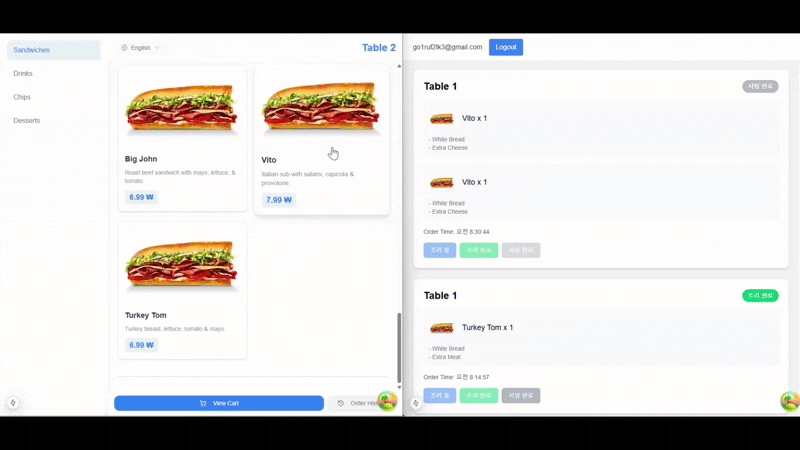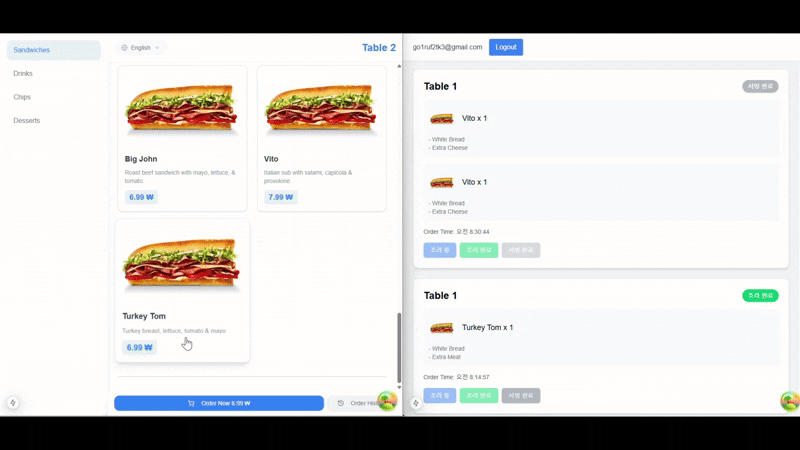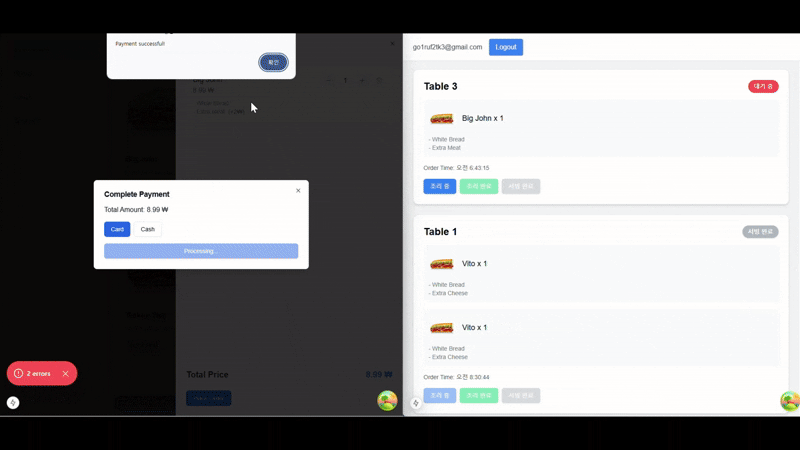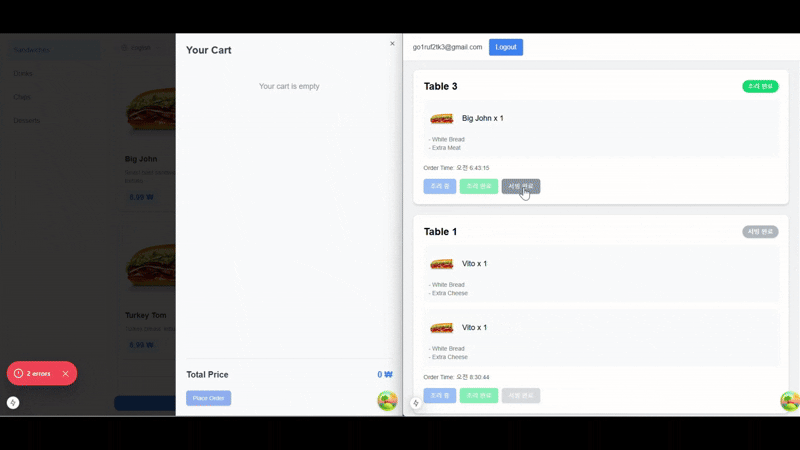
결론: 실시간 데이터 최적화는 선택이 아니라 필수다
- 실시간 시스템이라고 해서 모든 데이터를 매번 전송할 필요는 없다.
- 변경 알림과 데이터 조회를 분리하면 트래픽을 줄이고 서버 부하를 최소화할 수 있다.
- 이벤트 로그 테이블을 활용하면 시스템 확장성도 크게 향상된다.
이번 경험을 통해, "빠르게 만드는 것" 과 "확실히 최적화하는 것" 사이의 균형을 다시금 고민하게 되었다.
실시간 데이터 처리 시스템을 설계할 때, 반드시 데이터 흐름과 부하 패턴을 고려해야 한다는 교훈을 얻었다.